- Published on
System Design: Database Replication
- Authors
- Name
- Full Stack Engineer
- @fse_pro


  |   |
|---|
Database replication is a fundamental concept in building scalable and highly available systems. It plays a critical role in ensuring data integrity, fault tolerance, and efficient data distribution across multiple nodes. In this article, we will explore the concepts of database replication, its types, and the benefits it offers in achieving scalability and high availability.
Table of Contents
- Introduction
- What is Database Replication
- Types of Database Replication
- Benefits of Database Replication
- Challenges of Database Replication
- Considerations for Implementing Database Replication
- Conclusion
- Resources
Introduction
In distributed systems, databases are often a central component that stores and manages data. As the load on the database increases, it becomes essential to scale the database to handle a higher volume of data and concurrent user requests. Database replication is a technique that allows data to be copied and synchronized across multiple database nodes, enabling scalability and high availability.
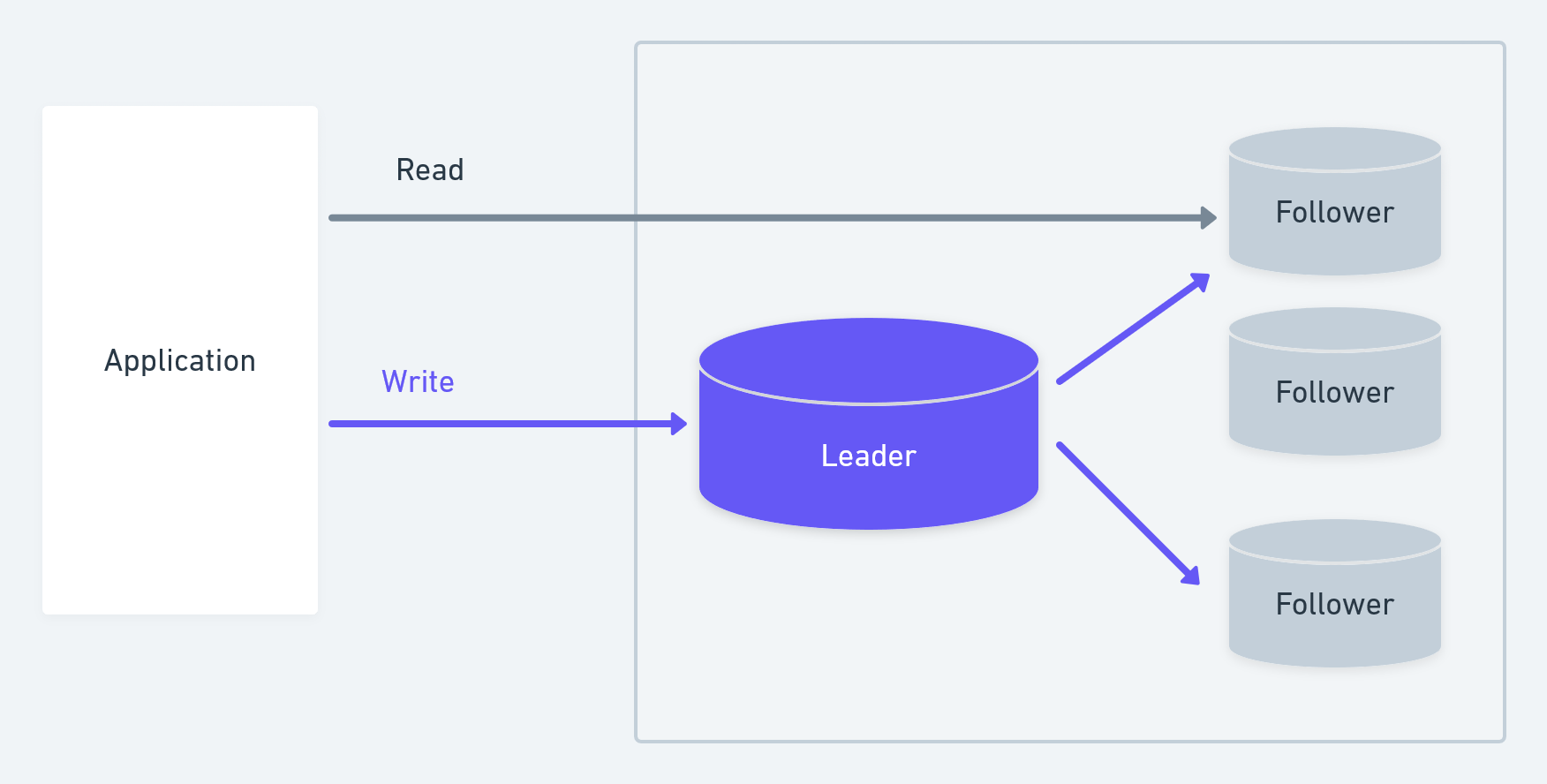
What is Database Replication
Database replication is the process of copying and synchronizing data from one database (the source) to one or more databases (the replicas). The primary goal of replication is to ensure that data remains consistent across all replicas, even as new data is added or existing data is updated.
Replication can be performed in real-time, near-real-time, or asynchronously, depending on the requirements of the application.
Types of Database Replication
There are three common types of database replication:
Master-Slave Replication
Master-slave replication involves a single database (the master) and one or more databases (the slaves). The master database is responsible for handling write operations (insert, update, delete), while the slave databases replicate the changes from the master.
How Master-Slave Replication Works
When a write operation occurs on the master database, the changes are recorded in a binary log. The slave databases then read the binary log and apply the changes, keeping the data in sync with the master.
Use Cases of Master-Slave Replication
Master-slave replication is commonly used to achieve read scalability. The master handles write operations, while the slaves handle read operations, distributing the read load across multiple nodes.
Benefits of Master-Slave Replication
Improved Read Performance: With read operations distributed across slaves, the system can handle more concurrent read requests, improving overall read performance.
Data Backup: Since the slave databases are exact replicas of the master, they can be used for data backup and disaster recovery purposes.
Master-Master Replication
Master-master replication, also known as bidirectional replication, involves two or more databases, and each database serves as both a master and a slave. All nodes can handle both read and write operations, and changes are replicated bidirectionally between the nodes.
How Master-Master Replication Works
In master-master replication, each node can independently handle write operations. When a write operation occurs on one node, the changes are replicated to the other nodes, keeping the data consistent across all nodes.
Use Cases of Master-Master Replication
Master-master replication is suitable for scenarios where high write concurrency is required. It allows write operations to be distributed among multiple nodes, reducing contention and improving write performance.
Benefits of Master-Master Replication
High Write Scalability: With write operations distributed among nodes, the system can handle a high volume of write requests, improving overall write scalability.
Fault Tolerance: In the event of a node failure, the system can continue to operate, as write operations can still be handled by the remaining nodes.
Multi-Master Replication
Multi-master replication is an extension of master-master replication and involves multiple nodes, where each node can serve as both a master and a slave.
How Multi-Master Replication Works
In multi-master replication, all nodes are capable of handling both read and write operations. Changes made to one node are propagated to the other nodes, ensuring that data is consistent across all nodes.
Use Cases of Multi-Master Replication
Multi-master replication is suitable for globally distributed applications where data needs to be updated across multiple regions or data centers.
Benefits of Multi-Master Replication
Geographical Distribution: Multi-master replication allows data to be updated in multiple regions or data centers, reducing latency and providing a better user experience for geographically distributed users.
High Availability: With multiple nodes capable of handling both read and write operations, the system can continue to operate even if some nodes become unavailable.
Benefits of Database Replication
Database replication offers several key benefits for building scalable and highly available systems:
Scalability
Database replication enables horizontal scalability by distributing the read and write operations across multiple database nodes. By offloading read operations to replica nodes, the system can handle a higher volume of read requests.
High Availability
With multiple database replicas, the system can continue to operate even if some nodes fail. If the master node becomes unavailable, one of the replica nodes can be promoted to the new master, ensuring continuous data availability.
Fault Tolerance
Database replication provides fault tolerance by ensuring that data is duplicated across multiple nodes. In the event of a node failure, the data can be retrieved from other nodes, preventing data loss.
Challenges of Database Replication
While database replication offers numerous benefits, it also introduces some challenges that need to be addressed:
Data Consistency: Ensuring data consistency across all replicas can be complex, especially in scenarios with high write concurrency.
Latency: In asynchronous replication, there can be a delay between changes made to the master and their propagation to the replicas, resulting in potential data inconsistencies.
Conflict Resolution: In bidirectional replication, conflicts can occur when the same data is updated on multiple nodes simultaneously. Handling these conflicts requires careful conflict resolution mechanisms.
Considerations for Implementing Database Replication
When implementing database replication, there are several considerations to take into account:
Replication Lag: In asynchronous replication, there may be a delay (replication lag) between the master and the replicas. Applications should be designed to handle this lag to avoid data inconsistencies.
Data Sharding: For very large databases, data sharding can be used in conjunction with replication to further improve scalability.
Monitoring and Maintenance: Monitoring the health of the replication process and regularly performing maintenance tasks are essential to ensure the reliability of the replication system.
Backup and Recovery: Replicas can be used for data backup and disaster recovery purposes. Regularly backing up the replicas ensures data durability.
Conclusion
Database replication is a fundamental concept in building scalable and highly available systems. By distributing data across multiple database nodes, replication enables horizontal scalability, fault tolerance, and high availability.
Master-slave replication is commonly used for read scalability, while master-master replication is suitable for high write concurrency. Multi-master replication is ideal for globally distributed applications.
While replication offers many benefits, it also introduces challenges such as data consistency and latency. Careful consideration and planning are required to implement an effective database replication system.
In conclusion, understanding the principles of database replication is crucial for architects and developers building robust and scalable systems.